The core idea
"It mostly works" is a trap. An audit gives you a baseline + failure map + fix roadmap—so you stop guessing.
If you're shipping an LLM app in production, "it mostly works" is a trap. The systems that quietly fail are the ones that: look fine in demos, cost more every week, and generate just enough wrong answers to kill trust.
An LLM audit is not a strategy deck. It's a baseline + failure map + fix roadmap so you can stop guessing. This post gives you: 9 symptoms that strongly indicate you need an LLM audit, a 30-minute self-assessment you can run today, and what an audit should produce (so you can evaluate vendors or do it in-house).
Context
Part of the LLM Audit hub: LLM Production Audit Framework. See also: GenAI vs AI System Audit, RAG Wrong Answers Triage.
Why this exists
If you're shipping an LLM app in production, "it mostly works" is a trap. The systems that quietly fail are the ones that:
- look fine in demos,
- cost more every week,
- and generate just enough wrong answers to kill trust.
An LLM audit is not a strategy deck. It's a baseline + failure map + fix roadmap so you can stop guessing.
The 9 symptoms (if you have 3+, you likely need an audit)
1) "Average quality looks okay" but users still complain
You're tracking a single score (or anecdotal feedback) and missing cohorts: language, intent, customer tier, document type, long-tail questions. Tell: support tickets say "wrong" or "made up" but your internal demos seem fine. What an audit checks: cohort-based eval + top failure categories.
2) Your RAG system returns answers that are confidently wrong
This is rarely "the prompt." It's usually: low recall retrieval (missing the right doc), context construction (wrong chunks stitched), stale content / freshness gaps, or mismatch between query and chunk granularity. Tell: "It cited something but the citation doesn't actually support the claim." What an audit checks: retrieval recall/precision proxies + citation validity sampling + failure taxonomy.
3) Cost is "randomly" exploding
Your OpenAI bill climbs without a clear product change. This often comes from: hidden retries and tool loops, prompt bloat (system prompt + long history), higher k / rerank everywhere, or model routing mistakes ("smart model" for easy queries). Tell: cost spikes correlate with peak hours or certain intents. What an audit checks: cost per successful task + token spend decomposition by stage.
4) P95 latency is bad, but nobody can point to the slow stage
Teams argue "the model is slow," but the bottleneck is often elsewhere: retrieval, rerank, tool calls, queueing, or timeouts/retries. Tell: P50 is okay but P95/P99 is painful. What an audit checks: stage-level tracing + queueing symptoms + timeout/retry policy review.
5) You can't separate retrieval failures vs generation failures
If you don't know whether the answer is wrong because you retrieved the wrong context, or you generated nonsense from correct context, you'll "fix" the wrong layer for weeks. Tell: every bug becomes a prompt patch. What an audit checks: minimum logging schema to classify failures.
6) You ship prompt/model changes without regression gates
Without eval gates, every improvement is a gamble. Tell: "It got better" this week, "it got worse" next week. What an audit checks: eval harness design + release checklist + golden set coverage.
7) Your agent/tool-calling is unstable
Agents fail in production because: tool errors are not handled deterministically, retries amplify latency/cost, the agent loops or calls tools unnecessarily, or outputs aren't validated before execution. Tell: "Sometimes it works. Sometimes it loops." What an audit checks: tool success rate, loop rate, tool latency distribution, validation rules.
8) You're stuck in "prompt optimization" hell
If the only lever you pull is prompt tweaks, you likely lack: a real baseline, a failure taxonomy, and a structured plan (retrieval / routing / caching / validation / monitoring). Tell: prompt changes help one intent and break another. What an audit checks: system design, not just prompts.
9) Enterprise/compliance questions block deals
You can't clearly answer: what you log / don't log, how PII is handled, whether vendors train on your data, or how you prevent prompt injection / data exfiltration. Tell: sales cycles stall on security reviews. What an audit checks: threat model + controls checklist + observability policy.
The 30-minute self-assessment (copy/paste template)
Score each item 0–2:
- 0 = not in place
- 1 = partial / inconsistent
- 2 = solid + used routinely
A) Measurement (10 minutes)
- We track task success with a clear definition (not just thumbs up/down). (0/1/2)
- We track groundedness/citation validity on a sample of production queries. (0/1/2)
- We track cost per successful task (not just cost per request). (0/1/2)
- We track P95 latency and TTFT separately. (0/1/2)
- We segment metrics by intent/cohort (language, tenant, doc type). (0/1/2)
B) Diagnosis (10 minutes)
- We can label a failure as retrieval vs generation vs tool failure quickly. (0/1/2)
- We have a known list of top 10 failure modes (taxonomy) with examples. (0/1/2)
- We can reproduce issues using saved traces (inputs, retrieval results, tool calls). (0/1/2)
C) Control (10 minutes)
- Prompt/model changes go through regression eval gates. (0/1/2)
- We validate outputs (schema/policy/citations) before executing tools or showing answers. (0/1/2)
- We have a routing policy (fast vs smart model) that is measured. (0/1/2)
- We have a basic security posture for LLM apps (PII, prompt injection defenses). (0/1/2)
Scoring
- 0–10: You're operating blind. An audit will pay back fast.
- 11–16: You have pieces, but likely fixing symptoms not causes.
- 17–24: You're ahead. An audit still helps prioritize ROI and prevent regressions.
Example: Minimum logging schema
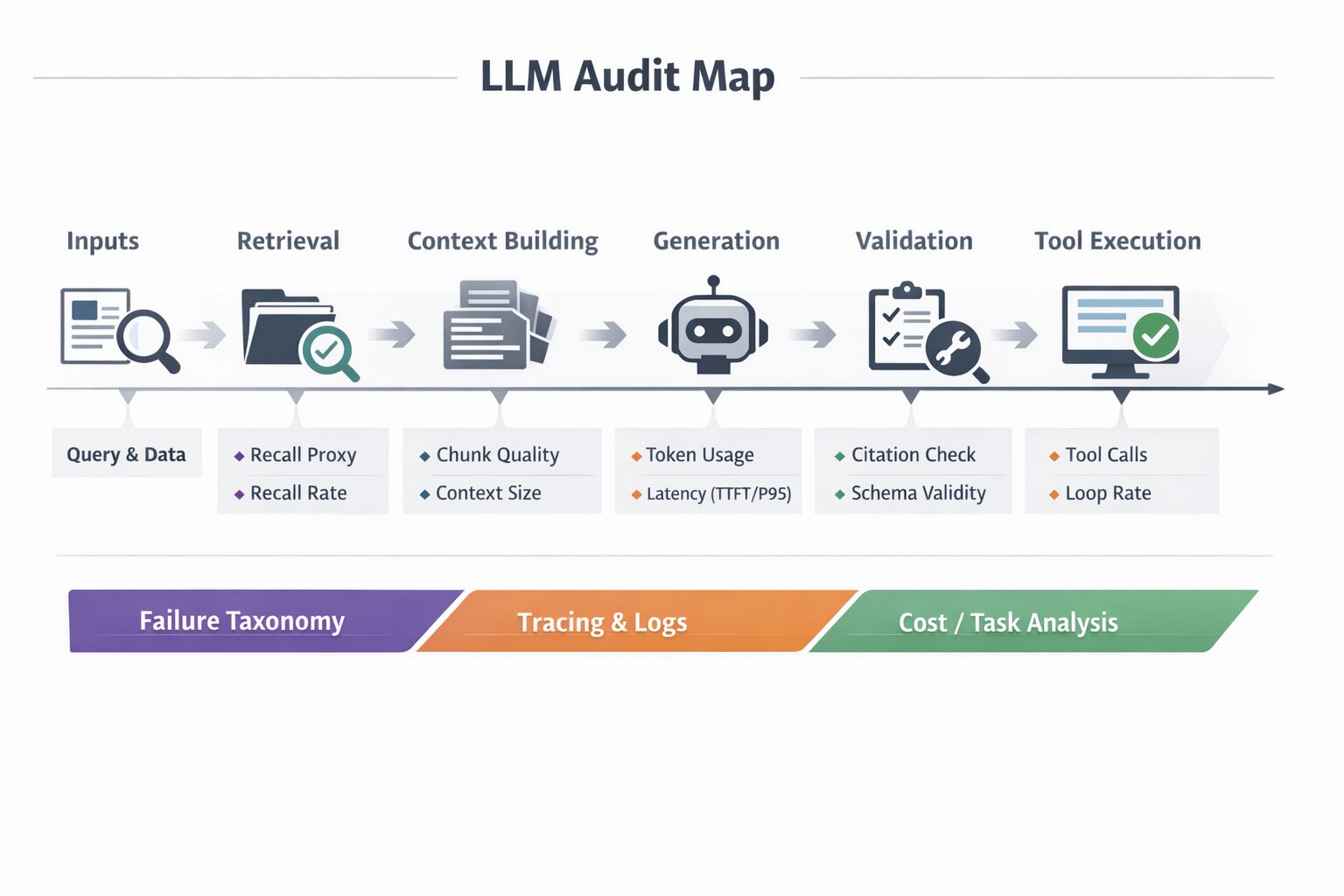
To support the Diagnosis items above—especially "reproduce issues using saved traces"—you need structured logs that connect input → retrieval → context → generation → validation → outcome. A real audit will recommend (or validate) an instrument plan. Here's a production-ready schema that covers the full pipeline:
With this schema, you can: classify failures (retrieval vs generation vs tools via failure_layer), reproduce issues (full trace from query to outcome), decompose cost and latency by stage, and segment by cohort (tenant, intent, locale). An audit will tailor this to your stack and privacy constraints.
What a real LLM audit should deliver
If you're buying an audit (or doing it internally), insist on these outputs:
- Baseline dashboard: quality, groundedness, cost/task, P95 latency, cohort breakdown
- Failure taxonomy with real examples
- Root-cause map: which failures are retrieval vs generation vs tools
- Fix roadmap: quick wins + deeper architectural changes
- Evaluation plan: what gets gated in CI, what gets monitored daily
- Instrument plan: minimum logging/tracing schema (see example above)
- Cost/latency teardown: where money/time actually goes
- Security/compliance notes: logging policy, PII controls, injection defenses (at least baseline)
Anything less is not an audit; it's a review.
Common trap: "We'll just tune prompts first"
Prompt tuning is valid, but only after you can answer:
- What failure mode are we targeting?
- How will we measure improvement?
- What cohorts might regress?
- What's the cost/latency trade-off?
If you can't answer those, prompt tuning is expensive roulette.
Next steps
Ready to take action?
Want the spreadsheet version of the self-assessment + audit scorecard? Download the LLM Audit Scorecard. Want a 30-minute triage call to sanity-check your measurement + logging? Request an LLM Audit / Assessment.
FAQ
Questions readers usually ask next
When should I get an LLM audit?
If you have 3+ of the 9 symptoms—e.g., users complain but demos look fine, RAG returns confidently wrong answers, cost is exploding, you can't separate retrieval vs generation failures, or you ship changes without regression gates—an audit will pay back quickly.
What does a real LLM audit deliver?
A real audit delivers: baseline dashboard (quality, groundedness, cost/task, P95 latency, cohort breakdown), failure taxonomy with examples, root-cause map (retrieval vs generation vs tools), fix roadmap (quick wins + deeper changes), evaluation plan (CI gates + daily monitoring), cost/latency teardown, and security/compliance notes.
Can I do the self-assessment myself?
Yes. The 30-minute self-assessment covers Measurement (task success, groundedness, cost per task, P95/TTFT, cohort segmentation), Diagnosis (failure labeling, taxonomy, trace reproducibility), and Control (regression gates, output validation, routing policy, security posture). Score 0–2 per item; 0–10 means you're operating blind.
If this sounds familiar…
Demos look fine, cost climbs, and users complain about wrong answers—but you can't point to the root cause.
What an audit fixes
Baseline metrics, failure taxonomy, root-cause map, and a prioritized roadmap—so improvement is measurable.
Want a 30-minute triage call?
We can sanity-check your measurement + logging and tell you whether an audit will pay back.Request an LLM Audit / Assessment.
Last updated
February 15, 2026





