Scalable architecture is not “add more servers.” It’s the set of decisions that lets a system grow—traffic, data, features, teams—without a proportional rise in tail latency, outages, unit cost, or operational chaos. This guide is written for teams operating real production systems: it includes decision tables, failure signatures, and a step-by-step design workflow you can apply during architecture reviews.
How to use this guide
If you’re designing new architecture: follow the workflow sections (metrics → quantify → design → capacity plan). If you’re already “slow at peak”: jump to Observability and Failure Isolation, then validate the constraint chain end-to-end. For a practical bottleneck workflow, read Observability for Scalability.
At scale, systems don’t fail because you ran out of servers. They fail because shared resources saturate, queues grow, dependencies amplify variance, and the tail becomes the user experience.
Scalable architecture meaning (and why teams get it wrong)
The most useful definition of scalable architecture is operational: a system can handle growth by adding capacity and evolving design while keeping user experience and operability within targets. Teams get it wrong when they treat scalability as a “pattern checklist” rather than a constraint problem.
Decision framing
A scalable architecture is one where you can answer: “If load doubles, what saturates first—and what do we do about it?” If you can’t answer that, you don’t have an architecture plan—you have hope.
A practical way to evaluate “scalable”:
- Predictable: you can forecast behavior as load grows (not just “it worked in staging”).
- Resilient: it degrades gracefully under failure instead of cascading.
- Efficient: unit cost rises slowly and intentionally (not via panic scaling).
- Operable: you can debug, deploy, and recover without heroics.
Looking for the foundations?
Start with the principles deep dive: Scalable Architecture Principles: 9 Rules That Survive Real Load .
Scalability vs performance vs reliability
Teams mis-prioritize work when they mix these:
- Performance: how fast the system responds at a given load (latency, throughput).
- Scalability: how performance changes as load grows when you add resources.
- Reliability: how consistently the system works over time (availability, durability).
Professional rule
If your p99 violates SLO during peak, you don’t have a scalability issue—you have a constraint issue. Solve the constraint first, then scale confidently.
Read the detailed breakdown: Scalability vs Performance vs Reliability: What Actually Matters at Scale .
Architecture scalability: what actually needs to scale
“Scale” is not just traffic. Most production systems must scale across multiple dimensions:
- Traffic: more requests, more concurrent users, higher peaks.
- Data: more rows, bigger indexes, higher read/write volume.
- Product: new features don’t multiply hot-path complexity.
- Teams: more engineers ship independently with clear ownership boundaries.
- Cost: unit cost remains stable and explainable.
- Geography: global latency + multi-region failure isolation.
Reality check
Systems rarely “fail suddenly.” They slow down quietly as coupling grows: deeper call chains, hotter data, larger queues, and more retries. The job of architecture is to make those failure modes visible and containable.
Metrics that define scalability in system design
Architecture decisions without measurement become opinion wars. The most practical metrics for scalable system design are:
Throughput
- Requests per second (RPS)
- Events/messages per second
- Transactions per second
Latency (use percentiles)
Average latency lies. Track percentiles: p50 (median), p95 (most users), p99 (tail latency). Tail latency becomes the customer experience under concurrency and variance. For growth framing, read: Performance Problems Are Growth Problems .
Availability & error budgets
Define SLOs and use error budgets to manage risk. This keeps scaling work grounded in customer impact, not preferences.
Saturation (approaching bottlenecks)
CPU alone isn’t the truth. Watch pools, queues, I/O, lock waits, and dependency concurrency. Saturation is often the earliest signal of a scaling failure.
Failure signature: “CPU is fine, but p99 is not”
- Metrics: rising queue depth, pool wait time, dependency latency variance
- Traces: time spent waiting (queueing / locks / downstream)
- Logs: timeout clusters, retry storms, saturation warnings
How to quantify scalability (curves, efficiency, and the knee)
Many teams track metrics but still can’t answer: “If traffic doubles, what happens?” To quantify scalability, you need a model that links load → latency → errors → cost.
1) The scalability curve (latency vs load)
Plot p95/p99 latency against RPS (or concurrency). Most systems show a “knee” point where tail latency rises non-linearly because a shared resource saturates (pool, I/O, lock contention, queue depth).
- Before the knee: scaling is predictable.
- After the knee: small load increases create large tail spikes and timeouts.
2) Scaling efficiency (resources → outcomes)
Horizontal scaling is only “real” if it increases throughput without destroying tail latency or unit cost. Track:
- Throughput efficiency: add 2x compute → do you get ~2x throughput?
- Tail stability: does p99 stay within SLO as load grows?
- Unit economics: cost per transaction as load grows.
3) Little’s Law: why queues become latency
Little’s Law: L = λW (items in system = arrival rate × time in system). In practice: when a dependency saturates, work accumulates in queues; backlog becomes added latency.
Practical takeaway: treat queue depth, pool wait time, and thread exhaustion as first-class latency metrics. If these rise, p99 follows—even when average latency looks fine.
Scalable architecture principles (practical rules)
These principles show up repeatedly in systems that survive growth. Each principle below has a “why it fails in production” lens.
1) Prefer stateless compute
Make instances replaceable. Keep session/state out of app memory. Stateless services enable autoscaling, safer deploys, and faster recovery. Read the deep dive: Stateless Services .
2) Minimize synchronous dependencies
Every synchronous hop adds tail latency and a failure surface. Keep hot paths short and dependency-light.
3) Control concurrency everywhere
Unlimited concurrency is how systems DDoS themselves. Use limits on requests, pools, workers, and downstream calls—plus backpressure.
4) Design for failure (explicit degradation)
Assume nodes die, networks flap, and dependencies become slow. Build timeouts, retries with jitter, circuit breakers, and graceful degradation intentionally.
5) Make retries safe with idempotency
At scale, retries are guaranteed. Idempotency prevents double-charging, double-ordering, or duplicated events.
6) Optimize for operability
If you can’t debug it, you can’t scale it. Invest in SLO dashboards, tracing, runbooks, and ownership boundaries.
Scalable architecture design: a step-by-step approach
This workflow avoids “pattern shopping.” It matches architecture choices to constraints, with explicit trade-offs.
Step 1: Define targets (SLOs) and growth assumptions
- Expected RPS and peak multipliers (e.g., 10x launch spikes)
- Latency targets (p95, p99)
- Availability targets and acceptable degradation
- Data growth (rows/day, retention, index growth)
- Cost constraints and unit economics
Step 2: Map critical flows and define the “fast path”
Your fast path is the set of actions representing most revenue or most traffic. Keep it short, stable, and dependency-light.
Step 3: Predict bottlenecks (where saturation will appear)
- Where is shared state? (DB, cache, external services)
- Which dependencies sit on every request?
- Where can hot keys/hot partitions emerge?
- Where can queue backlog build and amplify tail latency?
Step 4: Design failure paths (what happens when dependencies slow)
Decide per dependency: fail fast, fallback, degrade, or queue. This is where scalable architectures differentiate themselves.
Step 5: Instrument and iterate (prove constraints)
Build observability as part of design. Load test, observe saturation, and iterate. Scalability is continuous. If you’re operating production and need a constraint-first workflow, see Observability for Scalability .
Capacity planning & load testing workflow (practical)
Capacity planning reduces guesswork by producing a clear output: a capacity envelope (safe operating range) for your architecture.
1) Define a workload model (not just “RPS”)
- Read/write mix, payload sizes, and endpoint distribution
- Cache hit ratio assumptions (CDN + app cache)
- Burst behavior (launch spikes, batch jobs, cron fanout)
- Critical business flows (checkout, auth, publish, search)
2) Use a test pyramid: component → service → end-to-end
- Component: DB queries, cache behavior, serialization, hot endpoints
- Service: realistic traffic vs a service + dependencies
- End-to-end: validate cross-service tail latency and user experience
3) Measure constraints, not just “performance”
- Latency percentiles: p50/p95/p99 by endpoint
- Errors: timeouts, retries, 5xx, dependency errors
- Saturation: pool wait, queue depth, worker concurrency, I/O wait, GC pauses
- Cost: CPU per request, cache footprint, DB amplification
4) Produce the capacity envelope
Output should be decision-grade: “At p95 < 200ms and error < 0.1%, we safely sustain X RPS until Y saturates (e.g., DB pool wait).”
Rule of thumb
If you can’t name the top 1–2 saturating resources under peak, you’re not doing capacity planning—you’re doing hope.
Scalable architecture patterns (and when to use them)
Patterns don’t create scalability. They address constraints. Most production systems combine multiple patterns.
| Decision | Optimizes for | Fails first | What to measure |
|---|---|---|---|
| Async queues | Throughput, smoothing bursts | Lag buildup, retry amplification | Queue depth, processing latency, DLQ rate |
| Multi-layer caching | Read scaling, cost | Stampedes, staleness | Hit ratio, miss bursts, origin load |
| Read replicas / CQRS | Read throughput | Lag, “read-your-writes” gaps | Replication lag, staleness, correctness incidents |
| Sharding | Write scaling, dataset limits | Hot shards, operational complexity | Shard skew, hotspots, cross-shard queries |
For a deeper catalog, see Scalable Architecture Patterns: A Practical Catalog .
Data at scale: caching, replication, partitioning, sharding
Data is where most scaling projects succeed or fail. Reads often scale first; writes are harder. Treat data strategy as a first-class architecture decision—not a refactor later.
Read scaling
- Caching for hot reads and expensive computations (with stampede protection)
- Read replicas to offload reads (with explicit correctness expectations)
- Search indexes for query-heavy filtering
- Materialized views for precomputed results
Write scaling
- Idempotency keys for operations that may retry
- Append-only logs for high-volume ingestion
- Partitioning/sharding when one node can’t keep up
- Explicit consistency model (strong vs eventual)
Failure signature: hot partitions / hot keys
- Metrics: uneven CPU/IO across shards, lock waits, write latency spikes
- Traces: repeated waits on the same DB calls/key ranges
- Logs: timeouts clustered around specific tenants/entities
Decision tables: pick the right pattern fast
Caching strategy
- Cache-aside: default; app controls invalidation; requires stampede protection.
- Write-through: stronger consistency; higher write cost.
- Read-through: simplifies app; can hide hot-key issues if not observed.
Queues vs streams
- Queue: background jobs with retries + DLQ; best for “do this once”.
- Stream: ordered event log + replay; best for fanout, derived views, analytics ingestion.
Rule: patterns are not trophies. If indexing, caching, and concurrency control solve the constraint, do that before introducing distributed complexity.
Async and event-driven scaling architecture
Async patterns reduce coupling and smooth spikes, but introduce new failure modes. Build them intentionally:
- Queues: retries, DLQ, visibility timeouts
- Streams: replay controls, schema evolution, consumer lag visibility
- Outbox: reliable publish after DB writes
Outbox in one sentence: write business data + “event to publish” in the same transaction, publish asynchronously. This prevents “order saved, event lost.”
Resilience: how to prevent cascading failures
Scalability and resilience are inseparable. As traffic grows, small failure rates become large incident rates. Use standard failure controls:
- Timeouts to prevent resource starvation
- Retries with backoff + jitter (only when safe)
- Circuit breakers to fail fast
- Bulkheads to isolate resource pools
- Graceful degradation to preserve the fast path
Failure signature: retry amplification
- Metrics: rising error rate + rising downstream RPS (paradox), queue depth growth
- Traces: repeated calls, increased fan-out, time spent waiting downstream
- Logs: timeout clusters, retry warnings, circuit open/close oscillation
Observability: measure, debug, and operate at scale
A scalable architecture you can’t observe becomes unscalable operationally. Build the pillars:
- Metrics: RPS, p95/p99, error rate, saturation
- Logs: structured, correlated, searchable
- Tracing: critical path visibility (bounded sampling/cardinality)
For a constraint-first workflow (metrics → traces → logs), read: Observability for Scalability . For LLM or RAG pipelines with similar constraints—p95 latency, retrieval quality, cost spikes—see Do You Need an LLM Audit? 9 Production Symptoms + Self-Assessment .
Operational truth
Most scaling failures are not “capacity problems.” They are visibility problems. Teams scale faster when constraints are obvious and measurable.
High scalability architecture: global traffic and multi-region
Global scale introduces global constraints: latency, replication, and regional failure isolation. Key decisions include:
Edge and CDN strategy
Use CDN for static assets and safe caching. Consider edge caching for selected dynamic content with strict invalidation rules.
Multi-region models
- Active-passive: simpler correctness; requires tested failover.
- Active-active: higher availability; requires conflict handling and careful invariants.
Abuse protection
At scale, abuse can look like growth. Rate limiting, quotas, and anomaly detection become architecture primitives.
Multi-region data models & failover (RPO/RTO)
Multi-region scalability is primarily a data problem. Decide how writes behave across regions, and define objectives:
Define RPO/RTO first
- RPO: acceptable data loss window.
- RTO: acceptable recovery time.
Common write models
- Single-writer: simplest correctness; best for strong consistency.
- Multi-writer: higher availability; requires conflict resolution and strict invariants.
Runbook requirement
Failover must be a runbook, not a belief: health criteria, traffic steering, replication verification, and DR drills.
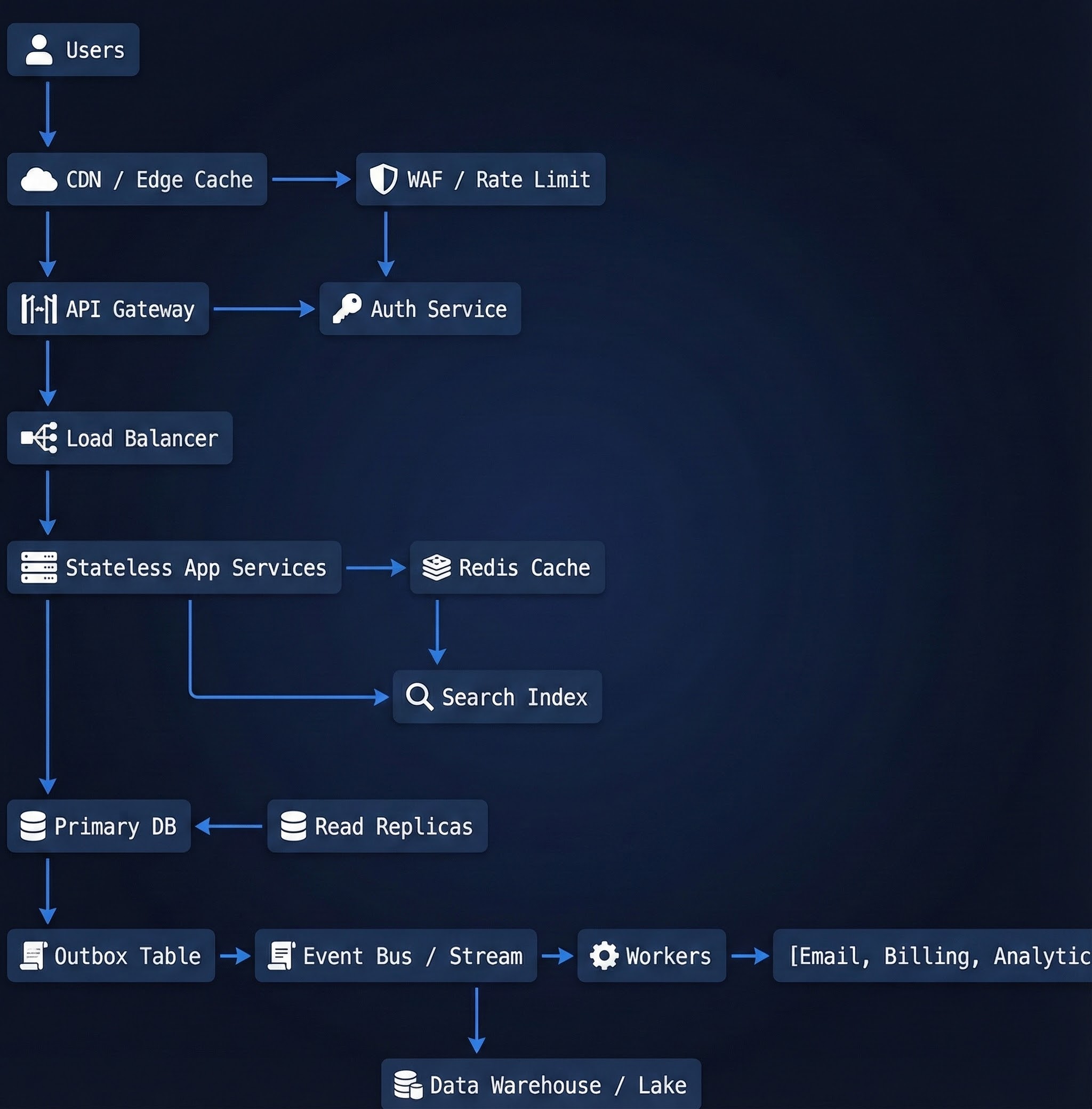
Scalable architecture reference architecture (blueprint)
A practical reference blueprint (adapt per product):
- Edge: CDN + WAF + rate limiting
- Gateway: routing, auth, throttling
- Compute: stateless services behind load balancers
- Cache: Redis for hot reads/session/locks (when needed)
- Data: primary OLTP + read replicas + optional search index
- Async: queue/stream + idempotent workers
- Observability: SLO dashboards + traces + logs
- Ops: config, secrets, CI/CD, rollback strategy
Scalable architecture diagram (reference + text flow)
Use this flow to make design review and incident response simpler by naming each hop explicitly:
- User → Edge (CDN/WAF/rate limit)
- Edge → Gateway (auth, routing, validation)
- Gateway → Stateless services (fast path kept short)
- Services → Cache (hot reads; singleflight/locks as needed)
- Services → OLTP DB (writes + critical reads)
- Services → Queue/Stream (async work, fanout, ingestion)
- Workers → downstream (indexing, exports, analytics)
- Observability across all hops (SLOs + saturation)
Scalable architecture examples (real-world templates)
These templates are starting points. The right architecture is the one that matches your constraints and failure modes.
Example 1: Ecommerce (spikes + correctness)
- Reads: CDN + cache-aside; search index for discovery
- Writes: idempotent checkout; inventory reservation; durable orders
- Async: confirmations, invoices, analytics via queue/stream
- Resilience: rate limit flash-sale endpoints; degrade recommendations first
Example 2: Social feed (read-heavy + fanout)
Choose between fanout-on-write (fast reads, heavy writes) and fanout-on-read (simpler writes, heavier reads), with hybrid strategies for power users.
Example 3: SaaS multi-tenant (fairness + isolation)
- Partition/shard by tenant_id
- Per-tenant quotas and rate limits
- Isolate queues per tier/noisy tenant
- Clear SLOs + budgets per tier
Example 4: Analytics ingestion (event volume)
- Append-only stream ingestion
- Near-real-time processing for dashboards
- Warehouse/lake for heavy queries
- Replay/backfill as a first-class feature
Example 5: LLM/RAG pipelines (retrieval, latency, grounding)
LLM and RAG systems scale across retrieval, context assembly, and inference—with constraints similar to traditional pipelines: tail latency, caching, saturation, and data quality. For wrong answers or retrieval issues, read RAG Wrong Answers Triage . To clarify audit scope (GenAI vs full system), see GenAI Audit vs. AI System Audit .
Migration path: from monolith to scalable (without chaos)
Many systems scale successfully without microservices. The practical path is: stabilize → modularize → isolate hot paths → introduce async → split only when ownership demands it.
Phase 1: Stabilize fundamentals
- Define SLOs + error budgets for top flows
- Instrument p95/p99, saturation, dependency health
- Fix obvious data bottlenecks (indexes, N+1, pool discipline)
Phase 2: Modularize for team scalability
- Clear boundaries: modules, ownership, deploy safety
- Move state out of process; keep compute replaceable
- Introduce concurrency controls and backpressure early
Phase 3: Move non-critical work off the request path
- Queues/streams for fanout, notifications, exports, indexing
- Idempotency keys + DLQs + replay strategy
- Protect the fast path with load shedding
Phase 4: Split services only when it reduces risk
- Split by ownership and failure domains (not by “entities”)
- Measure whether the split improves operability and incident isolation
- Avoid deep synchronous call chains; prefer events where possible
Anti-patterns that destroy scalability
- Deep synchronous call chains that amplify tail latency and failure risk
- No backpressure leading to cascading failures under spikes
- Database as a queue (polling tables becomes painful)
- Microservices too early (ops complexity overwhelms teams)
- Hot keys (global counters, single-tenant dominance)
- Caching without invalidation strategy (stale bugs become “random incidents”)
- No tracing/SLOs (debugging becomes guessing)
Checklists, FAQs, and glossary
Fast path checklist
- Minimize synchronous dependencies
- Cache hot reads with stampede protection
- Timeouts + circuit breakers on network calls
- Concurrency limits (requests, pools, workers)
- Monitor p95/p99 + saturation signals
Write path checklist
- Idempotency keys for retryable operations
- Outbox/event publishing strategy for downstream work
- Hot key mitigation (avoid global counters)
- Partition/shard plan when growth demands it
FAQ
Can a monolith be a scalable architecture?
Yes. A modular, stateless monolith behind a load balancer can scale very far. Data and operability are usually the limits.
What’s the fastest scalable architecture win?
Often: caching + query optimization + moving heavy work to async. Validate constraints before changing architecture.
What makes a highly scalable architecture?
Replaceable compute, controlled concurrency, async processing, scalable data strategy, and constraint-first observability.
Glossary
- Architecture scalability: ability to handle growth without unacceptable degradation.
- Backpressure: slowing upstream producers when downstream is overloaded.
- Bulkhead: isolating resources so one failure doesn’t take down everything.
- Cache stampede: simultaneous cache misses overwhelm the database.
- CQRS: separating read and write models to scale independently.
- Idempotency: repeating an operation produces the same business effect.
- Outbox pattern: writing events in the same transaction and publishing asynchronously.
- Tail latency: high-percentile latency (p95/p99) defining user experience at scale.
Need a constraint map for your production system?
If your architecture is “fine on average” but breaks at peak, start with an end-to-end constraint audit. Request an AI System Audit. If you run LLM or RAG in production and see wrong answers, latency spikes, or cost drift—check Do You Need an LLM Audit? 9 Production Symptoms for a 30-minute self-assessment.





